How are embeddings multiplied with weight matrices
Let’s walk through exactly how WQW_QWQ (the query weight matrix) is multiplied with the input embedding, using a small example with embedding size = 5.
🧠 Context: What is WQW_QWQ?
In a Transformer, we compute the Query (Q) vector for each token like this: Q=X⋅WQQ = X \cdot W_QQ=X⋅WQ
Where:
- XXX is the input embedding matrix (token representations)
- WQW_QWQ is a learnable weight matrix that projects from embedding size to query size (often the same size)

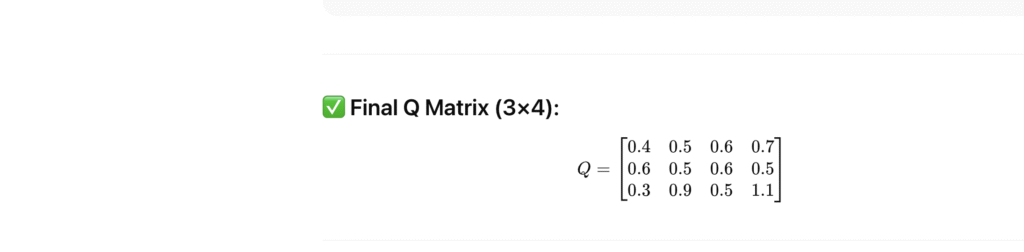
🔸 Token 1:
Q[0] = [1, 0, 0, 1, 1] • W_Q
= [1×0.1 + 0 + 0 + 1×0.1 + 1×0.2,
1×0.2 + 0 + 0 + 1×0.1 + 1×0.2,
1×0.3 + 0 + 0 + 1×0.1 + 1×0.2,
1×0.4 + 0 + 0 + 1×0.1 + 1×0.2]
= [0.4, 0.5, 0.6, 0.7]
🔸 Token 2:
Q[1] = [0, 1, 1, 0, 0] • W_Q
= [0+0+0.6+0+0, 0+0.5+0+0+0, 0+0+0.6+0+0, 0+0.5+0+0+0]
= [0.6, 0.5, 0.6, 0.5]
🔸 Token 3:
[2] = [1, 1, 0, 0, 1] • W_Q
= [1×0.1 + 1×0 + 0 + 0 + 1×0.2,
1×0.2 + 1×0.5 + 0 + 0 + 1×0.2,
1×0.3 + 1×0 + 0 + 0 + 1×0.2,
1×0.4 + 1×0.5 + 0 + 0 + 1×0.2]
= [0.3, 0.9, 0.5, 1.1]
Summary
- Input embedding XXX shape: seq_len×embed_size\text{seq\_len} \times \text{embed\_size}seq_len×embed_size
- Weight WQW_QWQ: embed_size×head_size\text{embed\_size} \times \text{head\_size}embed_size×head_size


